Trải nghiệm DuckLake và DuckDB trên AWS S3

I. DuckLake và DuckDB
Tính đến thời điểm này DuckDB đang ở phiên bản 1.3 và DuckLake đang ở phiên bản 0.2. Ngay khi mình lướt trúng bài viết trên LinkedIn về sự xuất hiện của DuckLake, mình đã rất hứng thú để có thể trải nghiệm nó ngay lập tức
Vậy DuckDB và DuckLake là gì?
1.1. DuckDB
DuckDB hướng tới là một Analytical Database system, tức là một hệ thống heavy-read sử dụng SQL
Những đặc điểm nổi bật của DuckDB:
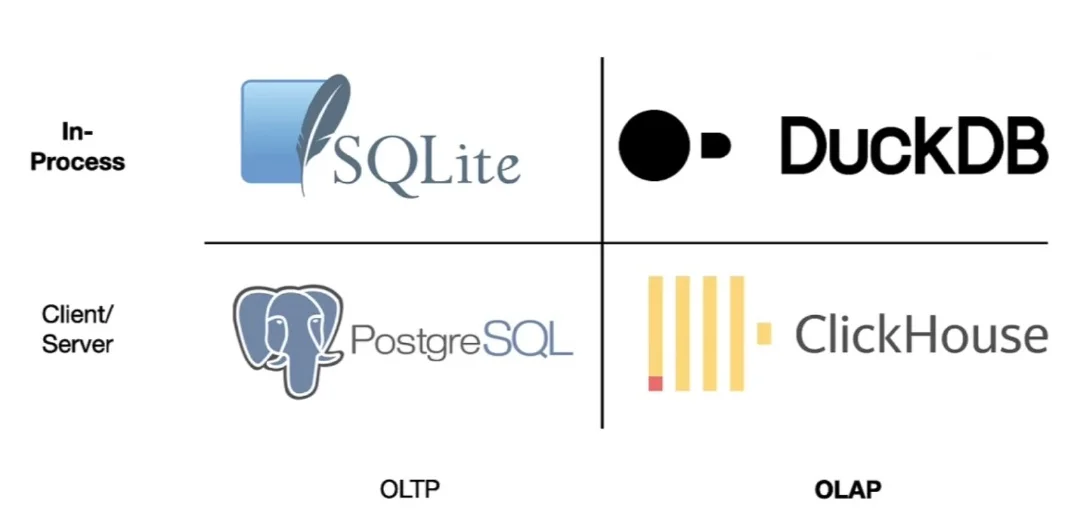
- Gọn nhẹ: Mọi người hẳn là không xa lạ gì với SQLite, một database engine rất gọn nhẹ, chỉ gói gọn trong một file, thường được sử dụng để chạy các ứng dụng nhẹ, đơn giản. DuckDB cũng sử dụng ý tưởng đó, nhưng mục tiêu của DuckDB là hướng tới các hệ thống analytic, tức là những hệ thống heavy-read. Bạn có thể thực hành tutorial của DuckDB qua link này , rất đơn giản
- Hỗ trợ SQL trên nhiều source: Đây là đặc điểm mình thích nhất. DuckDB hỗ trợ kết nối đến khá nhiều Data Sources, phổ biến nhất là CSV, JSON, PostgreSQL, Parquet, AWS S3, Azure Blob Storage, Excel, thậm chí là Pandas Dataframe, Numpy, Arrow. Tức nghĩa là bạn chỉ cần kết nối với các Data Source này là có thể viết SQL. Mình từng làm việc với Pandas xử lý file CSV và cảm thấy code không gọn gàng bằng SQL cho cùng một kết quả.
- Hỗ trợ SQL Syntax rất mạnh: Vì sinh sau đẻ muộn nên DuckDB kế thừa được rất nhiều cú pháp SQL của các hệ quản trị cơ sở dữ liệu lớn. Có thể nói, nếu bạn quen với việc sử dụng PostgreSQL, Oracle, SQL Server,… thì khả năng code của bạn vẫn chạy được trên DuckDB rất cao.
- Nhanh, có thể scale: DuckDB hỗ trợ heavy-read, tổ chức theo dạng columnar database, và xử lý trên Memory nên chạy rất nhanh và có thể scale (miễn là memory của bạn còn có thể scale được)
- Miễn phí, Open source
1.2. DuckLake
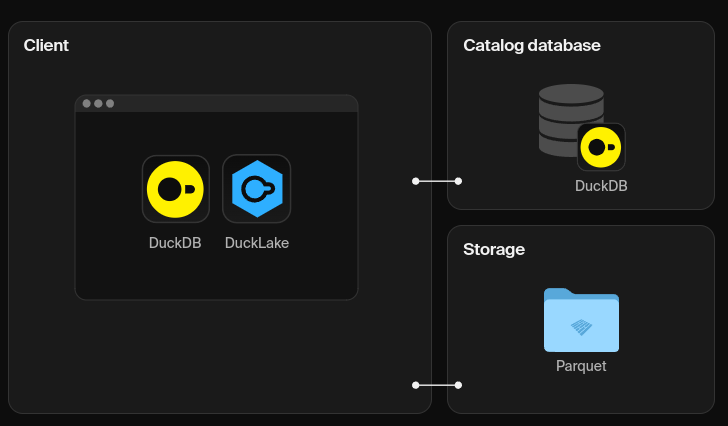
DuckLake được phát hành lần đầu vào ngày 27-5-2025, là một Lakehouse Format. Trước đó chúng ta đã có những format khác như Iceberg, Hudi, Delta Lake. Nhưng điểm khác biệt của DuckLake chính là việc quản lý Catalog bằng DB engine (PostgreSQL, SQLite, MySQL, DuckDB) trong khi các format khác quản lý bằng các file json, avro. Theo như tuyên bố của DuckLake, cải tiến này giúp cho việc lấy thông tin catalog nhanh hơn thay vì quét tất cả các file metadata như cách làm của các format khác vì các Database đã có thế mạnh xử lý những truy vấn có lượng IO cao, xử lý đồng thời, tối ưu câu truy vấn,…
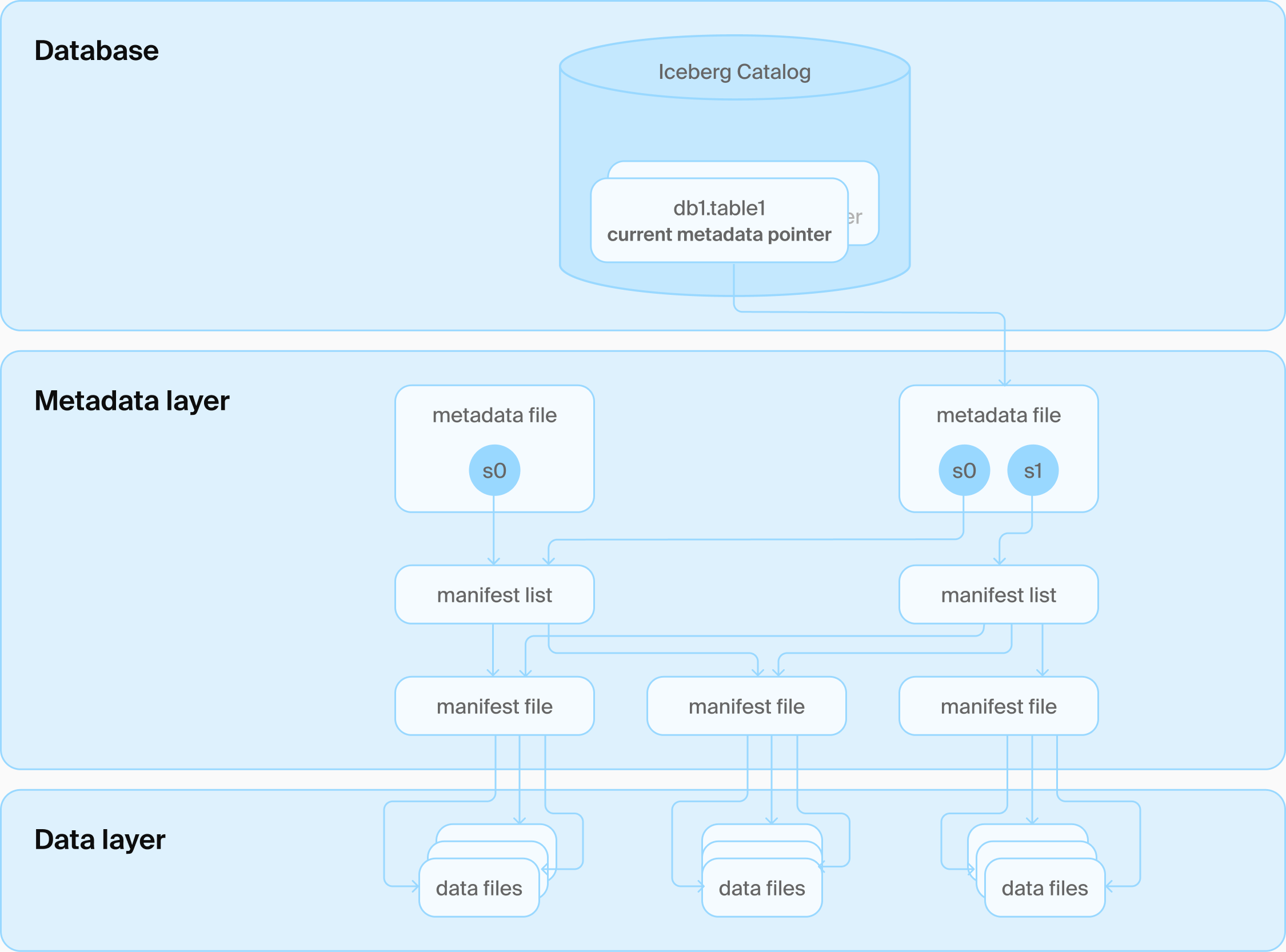
Iceberg Catalog Architecture
DuckLake’s architecture: Just a database and some Parquet files
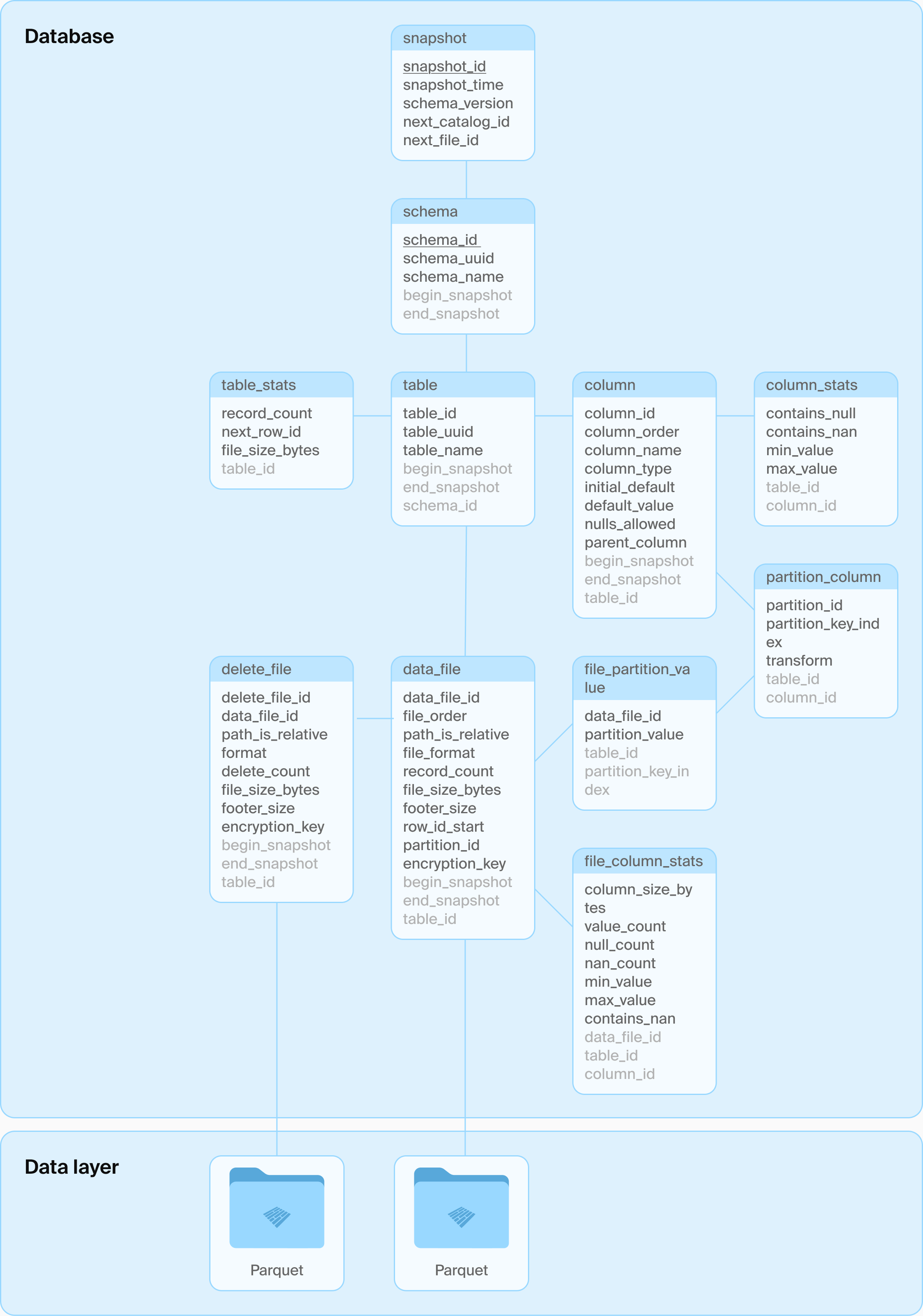
Cách tổ chức trong Database của DuckLake
Với vai trò là một Data Engineer đang làm việc với Data Lakehouse, mình khá thích ý tưởng của DuckDB và DuckLake mang lại
II. Thực hành cơ bản
Tại thời điểm viết bài, DuckLake còn khá mới mẻ, nên những tính năng hay ho sẽ còn nhiều ở phía trước. Hiện tại thì mình sẽ bắt đầu với những tính năng đã có
2.1. Cài đặt DuckDB, DuckLake
1
pip install duckdb
1
2
3
4
5
6
7
8
9
10
11
12
import duckdb
connection = duckdb.connect(':memory')
connection.execute('''
INSTALL aws;
LOAD aws;
INSTALL httpfs;
LOAD httpfs;
INSTALL parquet;
LOAD parquet;
INSTALL ducklake;
LOAD ducklake;
''')
2.2. Load AWS Credentials
1
connection.execute('CALL load_aws_credentials();')
hoặc nếu bạn chưa cấu hình AWS credential vào máy thì có thể nhập trực tiếp key (không khuyến khích)
1
2
3
4
5
6
7
8
connection.execute('''
CREATE SECRET (
TYPE S3,
KEY_ID '<Access Key id>',
SECRET '<Secret access key>',
REGION '<region>'
);
''')
2.3. Attach DuckLake Catalog
Bước này nhằm xác định đường dẫn của data lakehouse trong S3
1
2
3
4
connection.execute('''
ATTACH 'ducklake:metadata.ducklake' (
DATA_PATH 's3://your-bucket/your-prefix/'
);''')
Thế là xong, bắt đầu thao tác với Data Lakehouse thôi
2.4. Create Table
1
2
3
4
5
6
7
8
9
10
connection.execute('''
CREATE TABLE IF NOT EXISTS metadata.customers (
customer_id INTEGER,
first_name STRING,
last_name STRING,
email STRING,
city STRING,
created_at TIMESTAMP
);
''')
2.5. CRUD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
insert_sql = '''
INSERT INTO metadata.customers VALUES
(1, 'Alice', 'Smith', 'alice@example.com', 'New York', CURRENT_TIMESTAMP),
(2, 'Bob', 'Johnson', 'bob@example.com', 'San Francisco', CURRENT_TIMESTAMP);
'''
update_sql = '''
UPDATE metadata.customers
SET city = 'Los Angeles'
WHERE customer_id = 2;
'''
delete_sql = '''
DELETE FROM metadata.customers
WHERE customer_id = 1;
'''
select_sql = ''' SELECT * FROM metadata.customers; '''
connection.execute(insert_sql)
connection.execute(update_sql)
connection.execute(delete_sql)
connection.execute(select_sql)
III. Kết bài
Vậy là ta đã qua những thao tác đầu tiên của Data Lakehouse sử dụng DuckLake trên nền tảng AWS S3. Công nghệ này giúp chúng ta cài đặt và thao tác với Data Lakehouse rất nhanh so với những công nghệ hiện tại
Tuy nhiên, như mình đã nói, hiện tại công nghệ này còn khá mới mẻ nên vẫn chưa hỗ trợ hết các yêu cầu nâng cao hơn. Hãy cùng chờ đợi những phiên bản tiếp theo nào