Data Lakehouse Series - Bài 1 - Giới thiệu về series
Mở đầu
Đây là một series bài viết mô tả về cách triển khai một hệ thống Data Lakehouse đơn giản. Với việc học bằng cách thực hiện dự án (Project-based learning) sẽ giúp chúng ta hiểu được cách mà các công cụ liên kết được với nhau thay vì chỉ đi đơn lẻ từng công cụ.
Để bài viết không bị quá dài, các bạn có thể tìm hiểu một số lý thuyết trên Internet để trả lời các câu hỏi như:
- Data Lake là gì?
- Data Warehouse là gì?
- Data Lakehouse là gì?
- Tại sao lại cần Data Lakehouse?
Ở đây nói một cách cơ bản, một Data Lakehouse có thể hiểu nó là một hệ thống Data Lake có khả năng truy vấn dữ liệu như một Data Warehouse. Lúc này thay vì ta có Data Lake và Data Warehouse tách biệt nhau trong cùng hệ thống thì với Data Lakehouse, tất cả chỉ cần tập trung về một chỗ
Chuỗi bài viết này sẽ mô tả từng bước để setup một Data Lakehouse, từ lúc dữ liệu được sinh ra, tới lúc dữ liệu được xuất hiện trên report
Bài toán dẫn nhập
Giả sử một tập đoàn siêu to khổng lồ có 2 công ty con kinh doanh 2 mảng khác nhau:
- Công ty A kinh doanh thương mại điện tử, số lượng dữ liệu tạo ra liên tục
- Công ty B kinh doanh bất động sản, vài tuần mới có một hợp đồng mới
Tập đoàn này muốn tổng hợp dữ liệu mua hàng của các công ty con để lập báo cáo. Tập đoàn này muốn biết rằng:
- Doanh thu theo từng tháng của tập đoàn là bao nhiêu, công ty nào có doanh thu nhiều nhất
- Khách hàng nào chi nhiều tiền nhất cho tập đoàn
Mô tả kiến trúc
Trong bài viết này mình sẽ sử dụng AWS Cloud Service. Mình thiết kế kiến trúc Data Lakehouse như sau
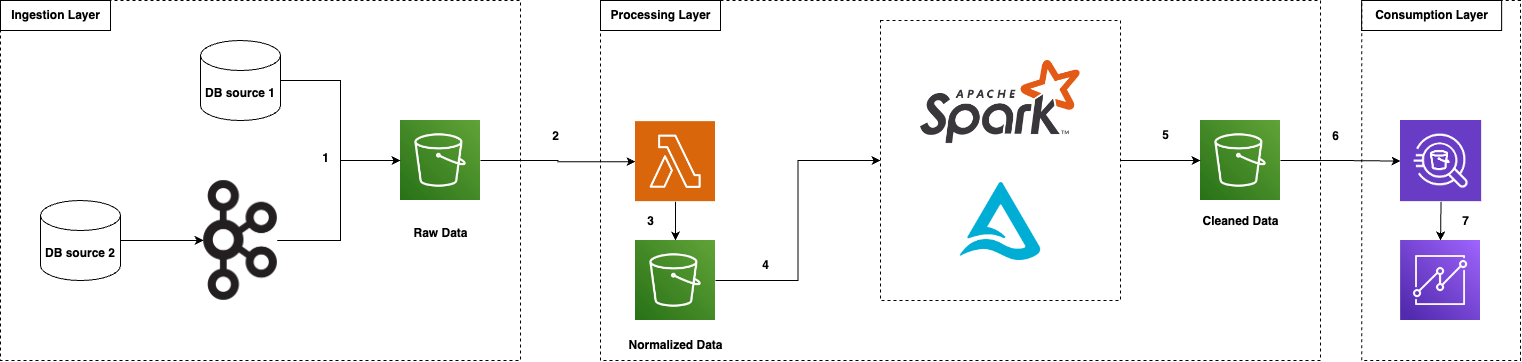
Giải thích một chút về luồng dữ liệu:
- Dữ liệu được Extract từ các nguồn và đổ vào S3: Stream (thông qua Kafka) hoặc Batch
- Dữ liệu được AWS Lambda đọc và tiến hành chuẩn hóa bao gồm: giải nén (nếu có), xóa trùng, xóa thừa, đổi format,…
- Sau khi xử lý, Lambda sẽ load dữ liệu vào S3
- Một Kubernetes Cluster có setup Apache Spark và Delta Lake, được quản lý bởi EKS sẽ đọc dữ liệu đã chuẩn hóa và tiến hành xử lý
- Apache Spark load vào S3 những dữ liệu đã làm sạch
- Athena sẽ đọc dữ liệu từ S3 bằng query để thực hiện việc tạo report
- Athena load kết quả vào Quicksights
Data Model
Cho dù là Data Lakehouse có thể truy vấn Data Lake như một Data Warehouse thì vẫn cần có Data Model
Data Model mình sẽ dùng trong bài này là Dimensional Modeling với Star Schema được thiết kế như sau:
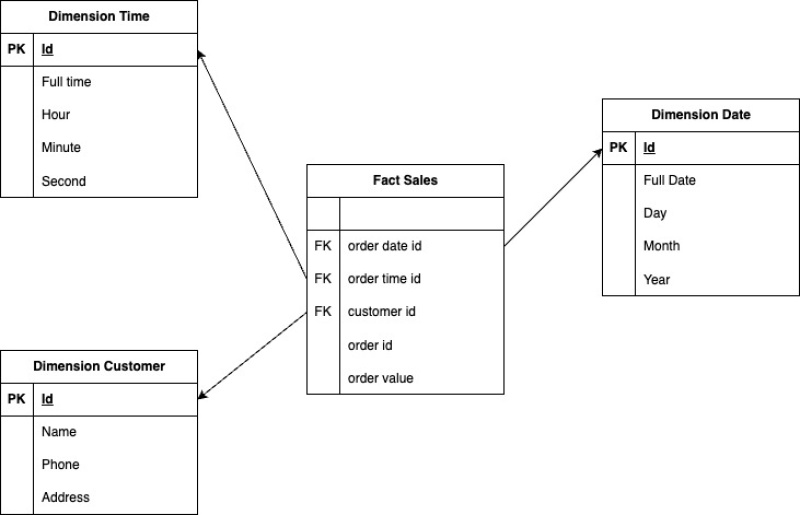
Bảng Dimension Date và Dimension Time có đặc điểm là chỉ cần tạo một lần nên ta không cần quá bận tâm về dữ liệu này. Dữ liệu sẽ chủ yếu biến động ở 2 bảng Dimension Customer và Fact Sales.
Khái niệm bảng Fact, Dimension và Star Schema trong Data Warehouse là gì các bạn có thể tham khảo trên Internet nhé
Nội dung chuỗi bài viết
Chuỗi bài viết này mình dự định sẽ chia thành các bài như sau
- Bài 1: Giới thiệu về series
- Bài 2: Extract dữ liệu thô vào S3
- Bài 3: Normalize dữ liệu với Lambda
- Bài 4: Cài đặt Apache Spark với Delta Lake
- Bài 5: Dùng Athena để truy vấn dữ liệu từ S3
- Bài 6: Tạo report trên Quicksights
Các bạn nhớ đón xem nhé