Data Lakehouse Series - Bài 2 - Extract dữ liệu thô vào AWS S3
Các bài viết cùng chủ đề:
- Bài 1: Giới thiệu về series: https://vinhtran1.github.io/posts/Vie-End-To-End-Data-Lakehouse-AWS-P1/
- Bài 2: Extract dữ liệu thô vào S3: Bài hiện tại
- Bài 3: Normalize dữ liệu với Lambda
- Bài 4: Cài đặt Apache Spark với Delta Lake
- Bài 5: Dùng Athena để truy vấn dữ liệu từ S3
- Bài 6: Tạo report trên Quicksights
Giới thiệu
Đây là bước đầu tiên trong toàn bộ luồng dữ liệu. Bước này nằm trong Ingestion Layer. Layer này có nhiệm vụ chủ yếu là thu thập dữ liệu từ các nguồn khác nhau về một chỗ gọi là Data Lake. Đặc điểm của layer này là khối lượng dữ liệu rất lớn, format dữ liệu đa dạng, dữ liệu ở dạng thô chưa qua bất kỳ bước xử lý nào. Tùy vào mỗi nguồn mà có các cách để thu thập khác nhau:
- Đồng bộ dữ liệu giữa 2 cơ sở dữ liệu (sync data between databases)
- Call API
- Web Scraping
- …
Tuy có nhiều kỹ thuật nhưng có thể chia những cách đó vào 2 loại chính: Batch và Stream.
Để minh họa 2 kỹ thuật đó, ở đây mình đã đề xuất nguồn dữ liệu có 2 cách để đổ về Data Lake. Xem hình dưới đây
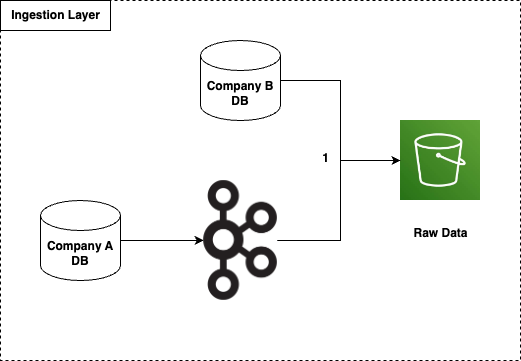
Như trong hình có thể thấy, có 2 nguồn dữ liệu của 2 công ty A và B:
- Công ty A cần stream dữ liệu vào Data Lake, thông qua Kafka
- Công ty B load dữ liệu định kỳ vào Data Lake
Ở đây ta sử dụng S3 làm Data Lake
Nhắc lại ở bài 1, Data Model của hệ thống này sau khi được làm sạch và tổ chức lại sẽ như sau:
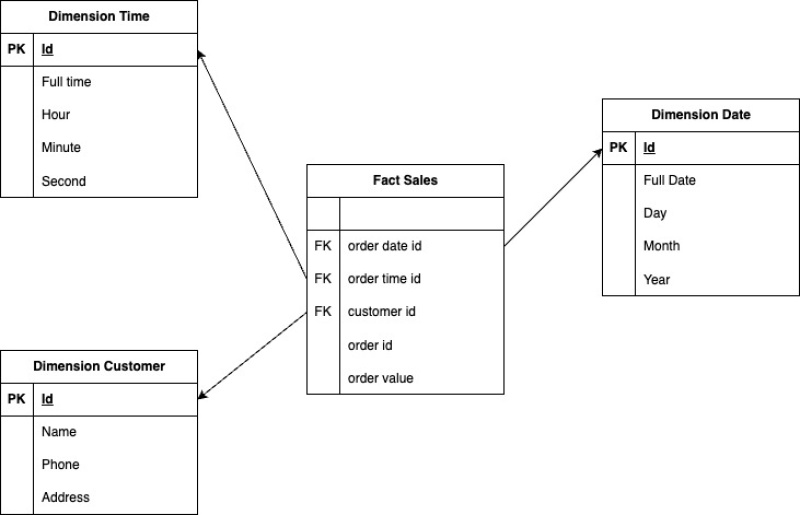
Như vậy ta sẽ cần tạo ra dữ liệu mẫu các bảng dimension date, dimension time, dữ liệu khách hàng của công ty A, công ty B, và dữ liệu mua hàng của những khách hàng đó.
Bây giờ sẽ tiến hình setup từng bước nhé.
Setup S3
Tạo một S3 bucket có tên tùy ý. Trong bài này sẽ đặt là data-lakehouse-pzoscg. Vì tên bucket là duy nhất trên toàn cầu nên cần phải đặt kèm theo một chuỗi ký tự random phía sau data-lakehouse để tránh bị trùng tên. Bạn có thể đặt tên khác khi thực hành
Ta sẽ quy định đường dẫn của các dữ liệu thô như sau:
- data-lakehouse-pzoscg/raw/companyA/customer: đường dẫn chứa dữ liệu thô về khách hàng của công ty A
- data-lakehouse-pzoscg/raw/companyA/transactions: đường dẫn chứa dữ liệu thô về các giao dịch của công ty A
- data-lakehouse-pzoscg/raw/companyB/customer: đường dẫn chứa dữ liệu thô về khách hàng của công ty B
- data-lakehouse-pzoscg/raw/companyB/transactions: đường dẫn chứa dữ liệu thô về các giao dịch của công ty B
- data-lakehouse-pzoscg/raw/dimension-date: đường dẫn chứa dữ liệu thô của dimension date
- data-lakehouse-pzoscg/raw/dimension-time: đường dẫn chứa dữ liệu thô của dimension time
Setup Project
Mở terminal và chạy câu lệnh
1
git clone https://github.com/vinhtran1/data-lakehouse-aws.git && cd data-lakehouse-aws
Cài đặt thư viện cần thiết
1
pip install -r requirements.txt
Mở file .env và thay các giá trị ACCESS_KEY_ID, SECRET_ACCESS_KEY, S3_DATA_LAKEHOUSE_BUCKET_NAME thành các giá trị tương ứng với mỗi người
1
2
3
export ACCESS_KEY_ID=
export SECRET_ACCESS_KEY=
export S3_DATA_LAKEHOUSE_BUCKET_NAME=data-lakehouse-pzoscg
Sau khi điền xong, kích hoạt file .env để tạo các biến môi trường
1
source .env
Truy cập vào thư mục P1_Extract_Data
1
cd P1_Extract_Data/
Setup Kafka
Để setup Kafka cluster có nhiều worker thì các bạn có thể xem lại bài viết của mình (https://vinhtran1.github.io/posts/Vie-Setup-Kafka-Cluster-Ubuntu-P1/). Còn trong bài này để đơn giản thì mình dùng Docker
Chạy câu lệnh sau trong terminal
1
docker-compose -f zk-single-kafka-single.yml up -d
Kiểm tra tình kết quả bằng câu lệnh
1
2
3
4
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2dd706a966de confluentinc/cp-kafka:7.3.2 "/etc/confluent/dock…" 4 seconds ago Up 3 seconds 0.0.0.0:9092->9092/tcp, 0.0.0.0:9999->9999/tcp, 0.0.0.0:29092->29092/tcp kafka1
564cb128d01b confluentinc/cp-zookeeper:7.3.2 "/etc/confluent/dock…" 4 seconds ago Up 4 seconds 2888/tcp, 0.0.0.0:2181->2181/tcp, 3888/tcp zoo1
Như vậy ta đã có một Kafka cluster gồm 1 zookeeper và 1 broker
Setup Code Extract data từ công ty A
Chạy câu lệnh sau để tiến hành produce message với số lượng tùy ý vào Kafka
1
python3 producer_company_A.py --num-customers 5 --num-transactions 20
- num-customers: số lượng message gửi vào Kafka. Mỗi message là một record đại diện cho một phép Insert, Update, Delete dữ liệu khách hàng
- num-transactions: số lượng message gửi vào Kafka. Mỗi message là một record đại diện cho một phép Insert dữ liệu mua hàng của khách hàng với thông tin khách hàng đã tạo trước đó
Tiếp theo chạy câu lệnh sau để tiến hành consume message.
1
python3 consumer_company_A.py
Mỗi message sẽ được lưu vào 1 file và đẩy lên S3
Sau khi chạy xong, kiểm tra kết quả trên trang AWS S3.
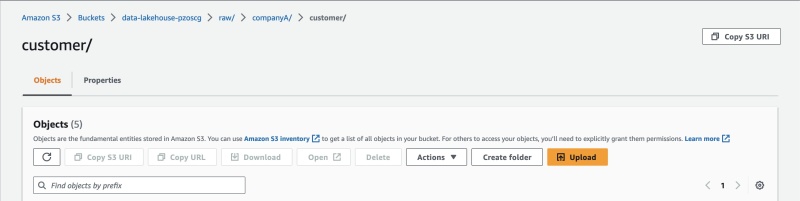
Kiểm tra dữ liệu khách hàng công ty A tại đường dẫn data-lakehouse-pzoscgraw/companyA/customer/
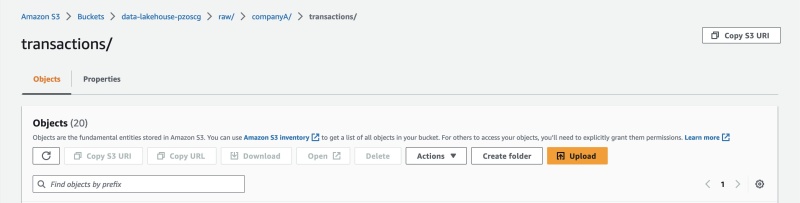
Kiểm tra dữ liệu transaction công ty A tại đường dẫn data-lakehouse-pzoscgraw/companyA/transactions/
Setup Code Extract data từ công ty B
Chạy câu lệnh sau để tạo dữ liệu mẫu và load vào S3
1
python3 extractor_company_B.py --num-customers 100 --num-transactions 3000
- num-customers: Số lượng record liên quan đến dữ liệu khách hàng: Mỗi record đại diện cho một phép Insert hoặc Update hoặc Delete dữ liệu khách hàng
- num-transactions: Số lượng record liên quan đến dữ liệu mua hàng của khách hàng. Mỗi record đại diện cho một phép Insert dữ liệu mua hàng dựa trên dữ liệu khách hàng đã tạo trước đó
Vì đây là dữ liệu dạng batch nên số lượng record không tương ứng với số file được tạo ra như dữ liệu dạng stream. Một file sẽ chứa nhiều record
Kiểm tra dữ liệu khách hàng công ty B tại đường dẫn data-lakehouse-pzoscgraw/companyB/customer/
Kiểm tra dữ liệu transaction công ty B tại đường dẫn data-lakehouse-pzoscgraw/companyB/transactions/
Load dữ liệu bảng dimension date, dimension time
Bảng dimension date và dimension time là hai bảng chỉ cần tạo một lần, nên ta sẽ tạo bằng cách upload file có sẵn vào S3
Chạy câu lệnh dưới đây để upload dữ liệu dimension date
1
python3 dim_date_extractor.py
Chạy câu lệnh dưới đây để upload dữ liệu dimension date
1
python3 dim_time_extractor.py
Sau khi chạy xong, kiểm tra thư dữ liệu tại đường dẫn data-lakehouse-pzoscg/raw/dimension-date/ và data-lakehouse-pzoscg/raw/dimension-time/
Kết luận
Như vậy là ta đã tạo được dữ liệu mẫu ở cả 2 dạng batch và stream. Bài tiếp theo ta sẽ dùng AWS Lambda để chuẩn hóa dữ liệu