Lean Data Lakehouse - Bài 1 - Giới thiệu
Lean Data Lakehouse - Bài 1: Giới thiệu project
Chuỗi bài viết này được lấy cảm hứng từ kinh nghiệm cá nhân mình, và bài viết của Dagster
I. Dẫn nhập
Sự phát triển của công nghệ đã dẫn đến sự tiến hóa của Data Warehouse thành một kiến trúc mới: Data Lakehouse
Định nghĩa về Data Lakehouse một cách chính thức cũng như vai trò của Data Lakehouse thì các bạn có thể tìm đọc trên Internet. Theo cá nhân mình hiểu theo một cách đơn giản thì:
Data Lakehouse = Khả năng chứa dữ liệu của Data Lake + Khả năng truy vấn dữ liệu của Data Warehouse
Tức là, với việc tổ chức dữ liệu thành các file có cấu trúc, ta có thể truy vấn dữ liệu từ các file đó để có thể tiến hành phân tích, báo cáo,… Điều này tận dụng được lợi thế lưu trữ giá rẻ của Data Lake và sức mạnh truy vấn của Data Warehouse
Trên lý thyết, Data Lakehouse thường chứa những dữ liệu rất lớn, sử dụng những công cụ xử lý rất mạnh mẽ như Spark để ETL. Kết quả là số tiền bỏ ra cũng không nhỏ. Nhưng theo kinh nghiệm đi làm của cá nhân mình và thêm một số quan điểm mà mình đọc được trên mạng, số lượng công ty có lượng dữ liệu đủ lớn đến mức bắt buộc phải sử dụng những công cụ big data là không nhiều
Vì vậy, trong bài viết này, mình sẽ implement End-to-End một dự án data Lakehouse phiên bản nhỏ hơn, tập trung vào việc tối ưu chi phí vận hành. Kiến trúc này hiện tại sẽ không phù hợp với những công ty lớn, mà phù hợp với công ty có lượng dữ liệu Too big for pandas, too small for Spark
Đây là bài đầu tiên trong chuỗi bài viết về Lean Data Lakehouse. Nội dung của từng bài sẽ như sau (Update sau)
II. Kiến trúc
Kiến trúc dự định sẽ như sau:
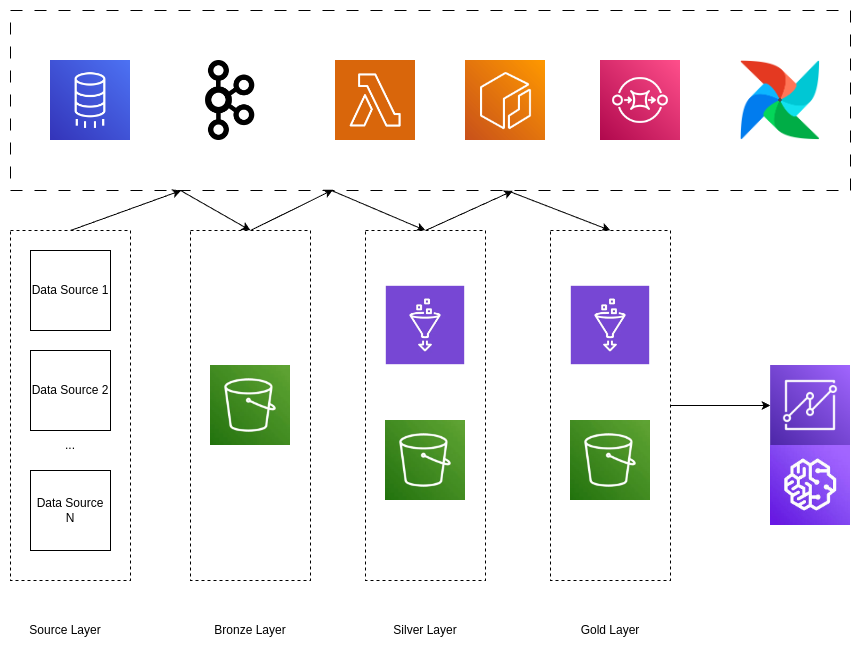
Vì mục đích là đạt được tối ưu chi phí nên trong kiến trúc này mình ưu tiên sử dụng những serverless service (Lambda, Glue Catalog, SQS) để giảm thời gian setup, khả năng scale cũng dễ dàng hơn
Giải thích sơ qua một chút về architecture:
- Data từ nhiều source trong source sẽ được tập trung về một nơi (bronze layer / Ingestion layer)
- Từ Bronze Layer tiến hành làm sạch dữ liệu, tổ chức lại thành dạng Iceberg table để có thể phục vụ cho việc truy vấn
- Tiếp tục, từ Silver Layer tiến hành ETL dữ liệu, các output của bước này sẵn sàng để được sử dụng bởi user
Do lượng dữ liệu không quá lớn nên chủ yếu mình sẽ thực hiện ETL trên AWS Lambda, và Orchestrate bằng Airflow Hẹn gặp các bạn ở bài tiếp theo của chuỗi bài này